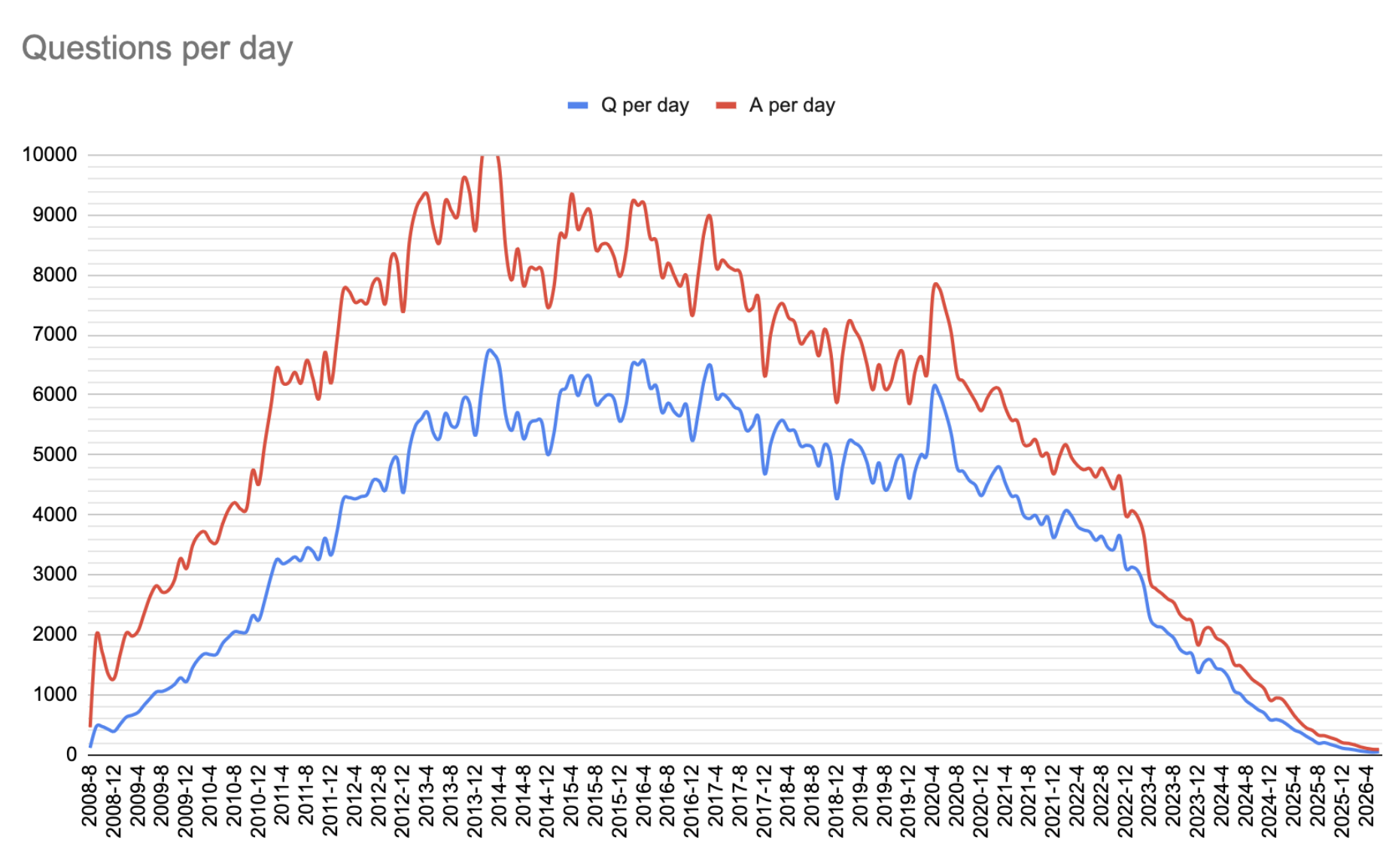
Last week, while on vacation in the northwestern corner of the United States, I was notified by a few people that my article Stack Overflow Hates New Users had made it onto a news site I was previously unfamiliar with, hackernoon (actually, the article was a part of a longer piece entitled The decline of Stack Overflow). It's rather amusing that an article I wrote over four years ago is still being cited by people, and I think that says a lot about the community surrounding the venerable question and answer site. I've been a user at said site for over four and a half years, and I have a few additional things I'd like to discuss.
Seeing as I have already written about things I learned using Stack Overflow, a list of my gripes with Stack Overflow, and a few suggested improvements for Stack Overflow, I won't rehash those here. What I would like to talk about, however, is how I think new users should approach the Stack Overflow experience:
Search, Search, and Search Again
I cannot stress this point enough. Before you ask a question on the site, search it to see if a similar question has already been asked. Over 95% of the time, at least one person will have already asked a question that should point you in the right direction. Don't use the built-in search, by the way; like many site search boxes, it's pretty lousy. Search with Google using the site:stackoverflow.com operator, and include any relevant keywords that could narrow your search (searching is an art form and non-trivial!).
Ask Detailed Questions
This is probably the biggest mistake new users make: they don't provide enough detail. Asking detailed questions takes some practice to master (I still haven't mastered this). Before you click that "Ask Question" button, ask yourself these questions:
- Is my question clear, concise, and easy to read?
- Have I mentioned what I've tried in the question I'm about to post?
- Have I provided all relevant details about my question (any specific library versions, or specific database flavors, or the operating system in use, etc.)?
- Do I have an idea of the direction to head, or am I flying blind? Have I made it known in my question that I know (or don't know) where to go?
- Where else have I looked for solutions? Did I mention these in my question?
Being short and to the point, yet detailed, is a difficult balance to achieve, but find that balance and you'll reap the rewards.
Be Patient
It's very difficult to get a lot of rep points in the beginning, so be patient; building trust takes time. Set mini-goals for yourself. I personally set a goal to get to 2000 rep points so I could edit other posts without having to have my edits approved. Once I reached that goal, I stopped worrying about points altogether (it's not worth worrying about)! Also, be courteous to everyone, even the jerks on the site (of which there are a number). Know-it-alls tend to like to flaunt their intelligence, and Stack Overflow is an outlet through which they can scratch that itch.
Join a Sister Site
I'm a big fan of Arqade, a sister site to Stack Overflow focused on video games. The community there is much more friendly and welcoming, and if you earn enough reputation at a site like that (only 200 points), you'll automatically get 100 bonus points on every other Stack Exchange site!
Stack Overflow is a great resource to use, but it's one that I keep at arm's length. These days, I tend to ask more questions than I answer, and I often find answers to questions I have through other people's postings. It's easy to get swept up in the competitiveness of the site at the beginning, but if you avoid doing that, you'll have a much more pleasant experience.